
Einführung
Abstraktionssichten: 复杂系统可以通过抽象层更好地描述。
Fokus auf relevante Funktionalitäten
抽象层通过接口(Interfaces)相互分离(durch Schnittstellen (Interfaces) voneinander getrennt):
使得每一层可以独立开发和实现,并且高层系统只需要与接口交互,而不需要了解底层实现。
z.B. Systemcalls: Implementierung durch Interface verborgen :
只需要直接用read(), write()这些命令,不需要关注/知道这些调用在内核中的具体实现。
Interfaces können die Software Sicht auf die Hardware definieren :
软件可以通过接口来访问硬件,而无需直接操作硬件。
Interfaces
Instruction Set Architecture (
ISA): 指令集架构Interface zwischen dem
BSundHardware是操作系统与硬件之间的接口besteht aud
User-undSystem-ISA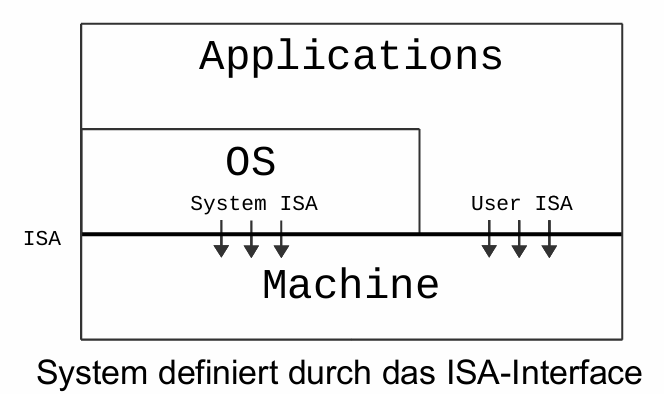
Application Binary Interface (
ABI): 应用二进制接口Interface zwischen
Anwendungenund demBetriebssystem是应用程序与操作系统之间的接口besteht aus dem
System Call Interfaceund derUser ISA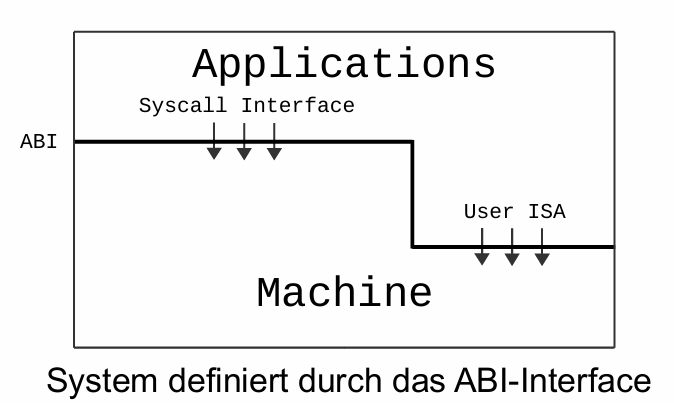
Die Sicht auf das System hängt von der Software-Perspektive ab:
如果是开发操作系统的话,则需要考虑操作系统与硬件的交互接口(isa);
而如果是开发普通软件的话,则更关注软件与操作系统的接口(abi),相当于通过操作系统来访问硬件。

Ein Hardware-System (physische Maschine) bietet eine Laufzeitumgebung für die darüberliegende Software:
- BS virtualisiert bereits: Prozesse, virtueller Speicher und Abstraktionen
Eine Virtuelle Maschine implementiert eine virtuelle Laufzeitumgebung:
- Abbilden von virtuellen auf physische Ressourcen
虚拟运行环境的分类
System Virtual Machines(系统虚拟机)
虚拟化整个系统
Process Virtual Machines(进程虚拟机)
仅为单个进程提供虚拟环境
Anforderungen an Virtualisierung 对虚拟化的要求
Equivalences/Fidelity:等效性虚拟化应该让操作系统和应用程序无需特殊修改(或者最小程度的改动)便可以在虚拟机上运行。
Resource Control/Safety (Isolation):隔离性必须确保虚拟机(的资源)彼此不会影响;Hypervisor需要控制所有底层资源
Efficiency/Performance:性能大部分指令应该直接在硬件上执行
系统虚拟机 (System Virtual Machines)
我们为什么需要系统虚拟机?
模拟(Emulation)使得操作系统可以在不同的 ISA上运行,并且在虚拟机中调试操作系统通常比在物理硬件(裸机)上更方便。
隔离(Isolation)受损或遭到攻击的 Guest OS 无法影响其他虚拟机,也无法修改 Hypervisor 本身。
安全性(Sicherheit)Hypervisor 更容易保护(代码量较小、权限较高)。
资源利用(Ressourcennutzung)物理硬件资源可以更好(更灵活)地分配和利用。
Hypervisor / Virtual Machine Monitor (VMM) 虚拟机监控器
Hypervisor负责给操作系统提供运行环境,通常会分为2类:
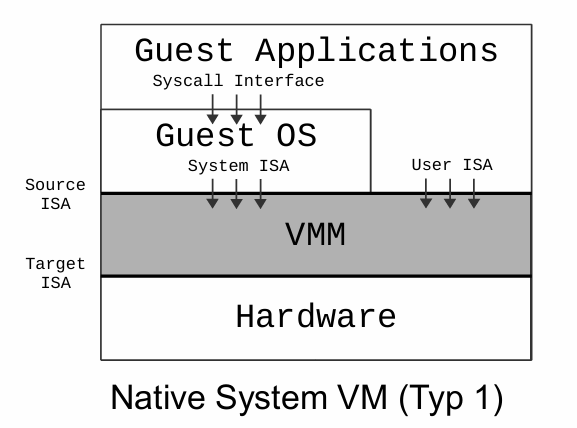
Typ 1Hypervisor /Bare-Metal-Hypervisor (裸机式)直接在物理硬件上运行容器,没有额外虚拟化层的存在。这种方式的主要优点在于性能的极致优化,因为没有虚拟化带来的开销。
比如 Xen, Hyper-V, VMware ESX。
Typ 2Hypervisor (托管式)依赖于宿主操作系统的服务( Verwendet Dienste des Host-BS)。
比如 KVM, VirtualBox, VMware Workstation。
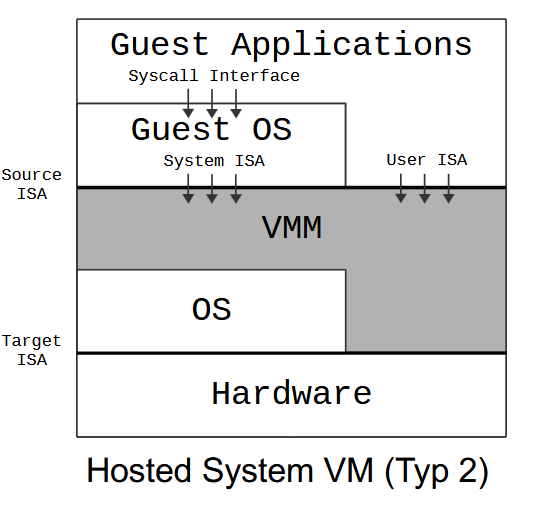
Hypervisor实现了一个虚拟的 ISA,同样分User- 和 System-ISA。
Hypervisor虚拟化整个物理机器,并且提供虚拟化硬件作为借口让Gast-BS可以在上面运行。可以使得Gast-BS以为/产生错觉(Illusion)自己对硬件拥有完整的控制权。但实际上对于Hypervisor来说,Gast-BS就只是个软件而已。
这样做的好处就是一个虚拟机可以运行任意操作系统,并且可以同时运行多个相同或不同的操作系统。
Hypervisor 负责控制和虚拟化系统的硬件资源:
- CPU 虚拟化(CPU-Virtualisierung)
- 内存虚拟化(Speicher-Virtualisierung)
- I/O 虚拟化(I/O-Virtualisierung)
并需要确保Gast-BS不能访问未分配给它的资源。
CPU 虚拟化(CPU-Virtualisierung)
CPU 的虚拟化方法一般是分以下3种:
半虚拟化(Paravirtualization):使用经过修改的操作系统 在虚拟机(VM)中运行,该 OS 知道自己处于虚拟化环境中。
设备驱动程序(Geräte Treiber)会通过 Hypercalls 与Hypervisor进行交互。
二进制翻译(Binary Translation):可以运行未经修改的操作系统,甚至可以在不同架构上运行(例如 x86 上模拟 ARM)。
Hypervisor会解释/模拟Gast-BS的部分二进制代码,所以会导致性能开销(Performance-Overhead)
这种Hypervisor的实现非常复杂。
硬件辅助虚拟化(Hardware-assisted Virtualization)可以运行未经修改的操作系统,可以实现高效的虚拟机(effizienten VMs),减少性能损失。所以是目前最主流的。
与普通操作系统中的内核空间(Kernel Space)与用户空间(User Space)不同(但相似)的是,我们这里会讨论的是高权限的 系统模式(System Mode) 和 用户模式(User Mode)。Hypervisor 会在系统模式(System Mode)运行,而Guest-BS则是会在用户模式(User Mode)运行。
某些在用户模式下执行的指令会被 Hypervisor 在系统模式下拦截,以确保Hypervisor 拥有对虚拟机的完全控制。
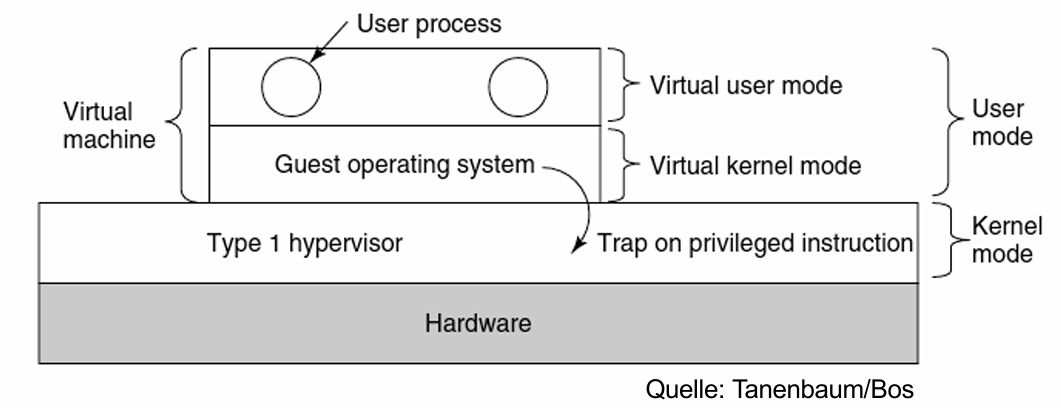
(套娃,User Mode里又有Virtual User Mode 和Virtual System Mode。)
ISA中的指令可以分为以下3类:
特权指令(Privileged Instructions):只能在系统模式(System Mode)下执行。
如果在用户模式(User Mode)下执行,则会触发陷阱(Trap),由 Hypervisor 处理。
敏感指令(Sensitive Instructions):其中又分为
控制敏感指令(Control-Sensitive Instructions):将修改系统配置(例如 修改页表(Page Tables))- 与
行为敏感指令(Behaviour-Sensitive Instructions):这些指令在不同模式下(用户模式 vs. 系统模式)的行为也是不同的。
无害指令(Innocuous Instructions):不属于前2类的则都属于这类。
虚拟化需要确保其中的敏感指令(Sensitive Instructions)必须是特权指令(Privileged Instructions)的子集。
反例可以参考x86架构中的POPF 指令(从栈加载标志寄存器 Flags)。
内存虚拟化(Speicher-Virtualisierung)
在正常的非虚拟化情况下,操作系统(OS) 会直接管理物理内存并分配给不同的进程,利用前面学到的Seitentabelle(Page Table)。但在虚拟化的情况下,Hypervisor 需要作为最高管理者(übergeordnete Instanz)负责内存资源分配,确保Gast-BS不能随意访问物理内存且只能“看到”分配给它的部分。
下面介绍内存虚拟化的2中方法:
影子页表(Shadow Page Table, SPT)硬件辅助的二级地址转换(Second Level Address Translation, SLAT)
影子页表(Shadow Page Table, SPT)
在这个方法里一共存在三个内存抽象层:
物理内存 (
Host-Physische Adressen, HPA)Hypervisor 对物理内存的抽象
即分配给Gast-BS的内存 (
Gast-Physische Adressen)。这些内存对于Gast-BS来说是连续的,但是在实际的物理内存里不一定连续。虚拟内存(
Virtueller Speicher)
Guest OS 维护自己的页表(这些页表 不会 被 MMU(内存管理单元) 直接使用。),而Hypervisor维护影子页表(SPT)。为了保持页表的同步,Gast-BS只能以只读(Read-Only)方式访问它的页表,任何写入页表的尝试都会被 Hypervisor 拦截(Trap),让Hypervisor好更新Gast-BS的页表与SPT。
相当于影子页表是中间的那层页表。
SPT的问题也很显而易见:管理起来非常复杂而且开销很高(hoher Overhead)。
二级地址转换(Second Level Address Translation, SLAT)
SLAT 由 CPU 提供硬件支持,将Gast-BS看到的 Gast 物理地址 (Gast-Physische Adressen) 映射到主机物理地址 (HPA)。Hypervisor 仅在 Guest OS 访问未映射的地址时才介入,减少性能开销。
例子: Intel Extended Page Tables (EPT), AMD Nested Page Tables (NPT)
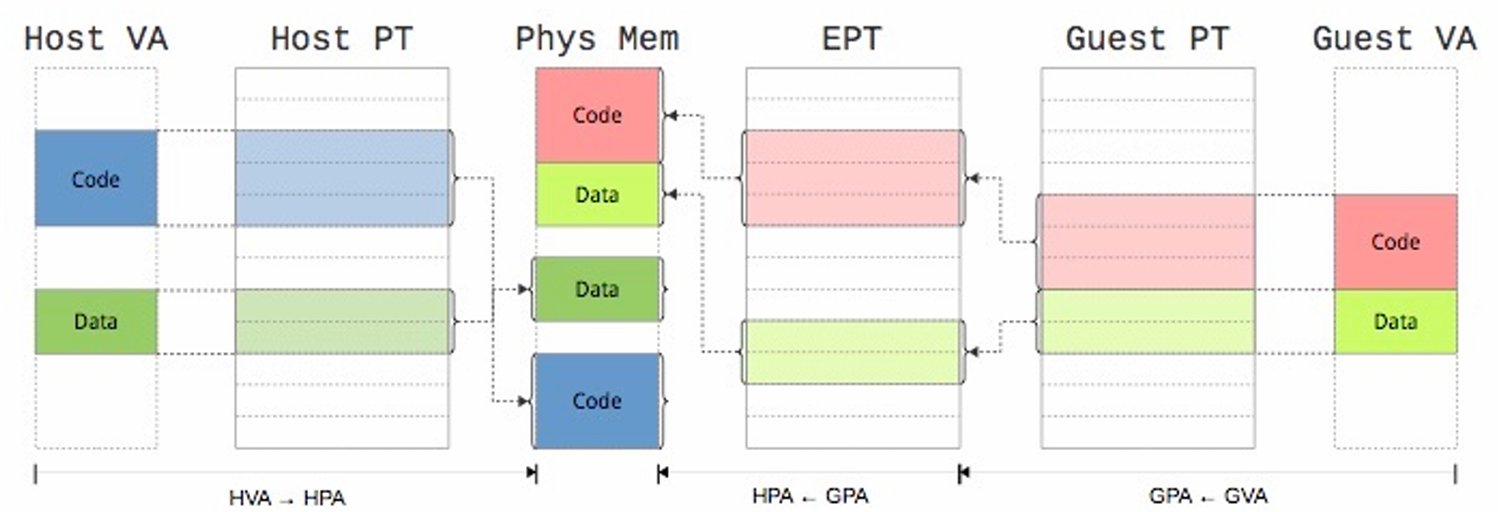
虚拟机的内存管理
跟进程管理的内存分配问题类似,我们也需要考虑该给每台虚拟机分配多少内存。
静态分配会导致不灵活,占用固定资源的问题。
动态分配的原理则是过量分配(Overcommitment)(假设并非所有 VMs 同时需要全部已分配的内存。)但这样会在回收已分配的内存时碰到问题,因为Hypervisor 无法知道哪些内存页是重要的,哪些可以释放。
为了解决这个问题我们可以使用 Ballooning (“balloon driver”):Gast-BS内部的软件与Hypervisor进行通信:(没有内存压力的虚拟机)释放内存(“气球放气”);申请内存(”给气球充气“)。
I/O 虚拟化(I/O-Virtualisierung)
介绍几种I/O 虚拟化的技术:
完整虚拟化/仿真(Full Virtualization/Emulation)
Hypervisor管理所有 Guest VM 的I/O请求,调度I/O资源。
Hypervisor 通过软件多路复用(multiplext)或仿真(emuliert)I/O 设备。
Hypervisor会拦截Guest VM的I/O请求,并将其转发到物理 I/O 设备。
优势:
- 高效 Gemultiplexte I/O-Geräte sind effizient;
- 透明 Transparentes Geräte-Management。
问题:
- 实现起来太复杂;
- Hypervisor 需要为多种 I/O 设备提供驱动程序。;
- 如果 I/O 设备完全仿真(Emulation),会产生较高的性能开销(Overhead)。
半虚拟化(Paravirtualization)
将 I/O 设备驱动分为两部分
使用拆分驱动架构(Split-Driver-Architektur)
后端驱动(Backend-Treiber):运行在 Hypervisor 或 I/O 处理 VM 内,实际管理物理设备。前端驱动(Frontend-Treiber):运行在 Gast-BS 内,与后端驱动通信。
优势:
- 开销更低(Geringer Overhead);
- 更容易实现;
- Guest OS 适配更灵活,可以通过 已有驱动支持新设备。
问题:
- Guest OS 需要额外修改或安装特定驱动。
设备域(Device Domains)
一台VM充当所有I/O设备的接口(在Xen中称为Domain 0或”dom0”),其他VMs通过这台VM访问I/O设备,而不是直接访问硬件。
直接 I/O 访问(Direct I/O)
使用硬件支持的 I/O 设备多路复用(Multiplexing)。
I/O-MMU(I/O 内存管理单元) 负责管理 Guest VM 的设备内存:
- 负责 I/O 地址和中断(Interrupt)的映射。
- 隔离 DMA(直接内存访问)请求,防止 VMs 互相干扰。
- 优势:
- Guest VM 直接访问物理设备,提高 I/O 效率。
- 部分 I/O 处理由硬件完成,减少 Hypervisor 负担。
单根 I/O 虚拟化(Single Root I/O Virtualization, SR-IOV)
I/O 设备本身支持虚拟化,将 一个物理设备拆分为多个虚拟功能( Virtual Functions,VF),会绕过Hypervisor的I/O处理。
Gast VM 看到的是一个独立的 I/O 设备,但实际上它共享了同一个物理设备。
(感觉大部分虚拟化的技术都是通过减轻Hypervisor的负担来提高效率的)
进程虚拟机(Process Virtual Machines)
跟系统虚拟机不同的是,进程虚拟机(Process VM)只给单个(或者多个)进程提供虚拟运行环境,使应用程序可以独立于底层操作系统和硬件架构运行。
Runtime会给用户空间进程(User-Space-Prozesse)提供虚拟运行环境,并且负责实现 ABI接口(由系统调用接口(Systemcall Interface)和用户指令集架构(User-ISA)组成)。简单来讲就是Runtime需要负责转换/翻译Systemcall和ISA的指令。
对应用程序来说,整个“系统”由 ABI 接口决定,而不依赖底层硬件或操作系统。
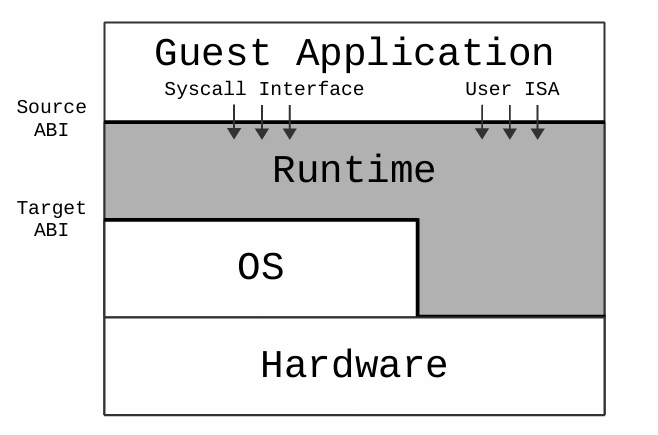
Runtime是类似于Hypervisor的中间层,但他们的核心作用之类的完全不一样。
进程虚拟机的优势:
仿真(Emulation):程序可以在不同 ISA(指令集架构)上运行。平台无关性(Plattform-Unabhängigkeit):程序可以在不同 OS 运行。性能优化(Performance-Optimierung):二进制优化器(Binary Optimizer)会优化代码。
高级语言虚拟机(High-Level-Language VMs, HLL VMs)作为进程虚拟机的一种,会提供一个与底层架构无关的虚拟 ISA( Plattform-unabhängige virtuelle ISA),使得应用程序不依赖特定的操作系统(OS)和硬件架构。主要是为了运行高级编程语言的代码。
比如说 Java Virtual Machine (JVM) 可以解释和执行 Java 字节码(Java Bytecode),让 Java 代码可以在 Windows、Linux、Mac 等不同平台 上运行。
如果多个进程需要共享资源并相互交互(interagieren),则通常使用操作系统级虚拟化(OS-level Virtualization)。
操作系统级虚拟化(OS-level-Virtualization)
操作系统级虚拟化(OS-level-Virtualization)可以运行多个隔离的应用进程,共享同一个操作系统(OS)。
Container
- Leichtgewichtige Virtualisierungsmöglichkeit 轻量化
- stellen eine Laufzeitumgebung für User-Space-Prozesse bereit
- BS wird nicht virtualisiert
- Isolation von Prozessen möglich
Container是OS-Level Virtualization的一种实现。
在传统的 Unix 操作系统中,一些资源是全局管理的,比如说PID, UID (User ID), IP-Addresse, Host- und NIS-Domainnamen,使得具有 root 权限的进程可以访问和影响其他进程,带来安全隐患。所以希望将他们隔离开。
Namespaces 是 Container 的基础:抽象出对系统全局资源的访问 (比如说Filesystem-Mount-Points, Netzressourcen, PIDs, etc.),将所有进程拆成disjoint subsets,使得每个subset里的进程会认为自己是整个系统中唯一的进程。
Jede Ressource ist eindeutig innerhalb eines Namespace-Containers
Bestandteile von Container unter Linux
Namespaces
作用:Benennung und Adressierung von Ressourcen,实现进程级别的资源隔离。
主要负责隔离。
在实际应用中,我们不总是需要隔离所有系统资源。因此,Linux 提供了多个独立的 Namespace,以实现更灵活的隔离方式,并避免不必要的资源浪费:
UTS: Unix Time Sharing (System)Isolieren System-Identifier (z.B.Host- und Domainnamen 主机名和域名)
例如,在 Docker 容器中,每个容器可以拥有自己的主机名,而不会影响宿主机。
IPC: Inter-Process Communicationisolieren IPC-Ressourcen 隔离进程间通信、
例如,不同的容器不能访问彼此的共享内存和消息队列,提高安全性。
Network:isolieren Netzressourcen 隔离网络设备、IP 地址、端口、路由表等,允许不同 Namespace 拥有独立的网络栈。
PID:isolieren PID-Räume
Prozesse in unterschiedlichen PID-Namespaces können dieselbe PID haben, aber eindeutig innerhalb eines PID-Namespace
Es können verschachtelte (engl. nested) PID-Namespaces erstellt werden 可以套娃
在同一 PID 命名空间内,进程可以正常通信;在不同 PID 命名空间之间,父 Namespace 可以向子 Namespace 发送信号,但子 Namespace 不能影响父 Namespace。
Mount:isolieren Mount-Points des Dateisystems 隔离文件系统挂载点,允许不同的 Namespace 看到不同的文件系统视图。
(在 Linux 中,挂载点(Mount Point) 是指将一个文件系统连接到目录结构中的特定位置,使其内容可以通过该目录访问。)
挂载类型 (Mount-Typ):
Shared Mount 共享挂载:接收+传递
该挂载点的 mount 和 umount 事件会在 Peer Group 之间传播。
例如,在 Shared Mount 上挂载一个新目录,所有共享该挂载点的进程都会看到这个变更。
Private Mount 私有挂载:不接收+不传递
挂载点不会接收,也不会向对等组(Peer Groups)传递事件。 Der Mount-Point empfängt und leitet keine Events zu Peer Groups weiter.
Slave Mount 从属挂载:接收+不传递
Slave-Mount-Points empfangen Events von einer Master Peer Group.
Unbinable Mount 不可绑定挂载:
Ist ein Private Mount, der nicht gebunden (Bind Mount) werden kann. 不能被绑定的私人挂载。
(Bind Mount指的是允许将一个目录或文件挂载到另一个位置,使其在多个路径下可见。)
Peer Groups(对等组):Peer Group 是一组共享 mount 事件的挂载点,当一个 Shared Mount 被创建时,它会被添加到某个 Peer Group。所有 Peer Group 内的挂载点都会同步 mount 和 umount 事件。
User:isolieren User- und Group-IDs 隔离用户 ID 和权限
Erhöhte Privilegien sind nur innerhalb des User Namespace gültig.
können auch verschachtelte User-Namespaces erstellt werden. 套娃
例如,容器内的 root 实际上是宿主机的普通用户,增强安全性。
Linux Control Groups (cgroups)
主要负责限制。
作用:
cgroups unterteilen Prozesse in hierarchische Gruppen 将进程划分为层次化的组
- 分配( Allozieren )和分发( verteilen )每一组的系统资源 (CPU, 内存等)
- 资源由独立的 cgroup 子系统表示
- Jedes Subsystem verwaltet eine Hierarchie an Prozessgruppen
Accounting
- Überwacht Seiten, die von den Prozessgruppen verwendet werden 监控进程使用的内存
Kontrolle
weiche Speichergrenzen
确保内存页会被回收(但不是强制的,即在系统压力下会优先释放,但不会立即强制回收)
harte Speichergrenzen
会触发 Out-of-Memory-Killer
- 所有该 cgroup 内的进程会被冻结。
- OOM Killer 可能会终止进程或调整内存限制。
- 如果内存使用量下降到限制以下,进程可以恢复运行。
Secure Computing Mode (Seccomp)
用于限制进程可以执行的系统调用(System Calls)。
提供 3 种模式:
Disabled:
未启用,可以调用所有 System Call
Strict:
只能调用4个:read(), write(), exit() 和 sigreturn()
(sigreturn() 是一个 系统调用(syscall),用于 从信号处理程序(signal handler)返回到被中断的进程上下文。)
调用其他的会触发SIGKILL信号。
Filter:
只能使用被过滤过的System Call。
Filter会基于Berkeley Packet Filter (BPF)。
库操作系统(Library OS)
其实虚拟机(VM)和Container还是有些问题的:
通用性(Universell):内核(Kernel)并未针对特定应用进行优化。额外开销(Overhead):包含未使用的组件,带来以下问题:- 镜像(Abbilder,指的是 VM 或容器的系统镜像(System Image),包含操作系统和应用程序的文件。)过大会导致部署(Deployment,指的是 将 VM 或容器的镜像部署到运行环境中的过程。)变慢。
- 攻击面(Angriffsfenster)过大,增加安全风险。
- 容器通常只为一个用户提供一个应用,所以包含许多不必要的功能。
所以我们可以考虑将 VM 作为一个应用进行编译(即 Library OS),用于创建一个最小化、专门针对特定应用优化的虚拟机。
Library OS 会像一个库(Bibliothek)一样运行。在编译过程中,仅包含所需的功能,整个系统可以通过编译器进行优化。一般只会运行一个进程(但支持多线程)。
Library OS 的理念可以理解为:将每个应用程序所依赖的 OS(操作系统) 的 personality(特性) 作为 library(库) ,使其独立地运行在该应用程序的地址空间上。
这种VM 被称为 Unikernel,意味着所有执行都在内核模式(Kernel Mode)进行,并且只有一个地址空间,因为整个 Unikernel 就是一个单进程应用。
缺点:应用程序必须经常进行调整(angepasset werden),因为它们在内部调用其他应用程序,但架构不支持这种调用。核心原因就是不支持多个进程交互。
例题
例题1
Wie viele PIDs hat ein Prozess unter Linux?
- Eine pro User
- Eine pro CPU
- Eine pro cgroup
- Eine pro Child
- Eine pro Prozessgruppe
- Eine pro PID-Namespace
答案:6。
例题2
Welche Voraussetzungen müssen für hardware-unterstützte Virtualisierung erfüllt sein?
- Gast kooperiert mit Host-Betriebssystem
- Syscall-Nummern im Gast- und Host-Kernel
sind identisch - Gast- und Host-ISA sind identisch
- Support durch Prozessor
- Peripheriegeräte unterstützen SR-IOV
- Gast-Adressen entsprechen Host-Adressen
答案:3,4.
解释: